Note
Go to the end to download the full example code.
Conditional Data Imputation¶
This example shows how to use ConditionalImputer for
conditional (observational) imputation when computing Shapley interactions.
Conditional imputation respects feature dependencies, unlike marginal
(interventional) imputation.
from __future__ import annotations
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import shapiq
Load Data and Train Model¶
X, y = shapiq.load_california_housing()
X_train, X_test, y_train, y_test = train_test_split(
X.values,
y.values,
test_size=0.25,
random_state=42,
)
n_features = X_train.shape[1]
model = RandomForestRegressor(
n_estimators=100,
max_depth=n_features,
max_features=2 / 3,
max_samples=2 / 3,
random_state=42,
)
model.fit(X_train, y_train)
print(f"Train R2: {model.score(X_train, y_train):.4f}")
print(f"Test R2: {model.score(X_test, y_test):.4f}")
Train R2: 0.7965
Test R2: 0.7431
Conditional Imputer¶
Set imputer="conditional" in TabularExplainer.
The imputer trains a gradient boosting model per feature to learn the
conditional distribution. Key parameters:
sample_size: samples drawn from conditional backgroundconditional_budget: coalitions per data point for trainingconditional_threshold: quantile threshold for neighbourhood
Explain a Single Instance¶
InteractionValues(
index=SII, max_order=2, min_order=0, estimated=False, estimation_budget=256,
n_players=8, baseline_value=2.0701874006108745,
Top 10 interactions:
(0, 1): 0.07128902713121714
(5,): 0.0526673761371985
(2,): 0.04183362760809132
(6, 7): -0.028495015287305605
(1, 7): -0.031168844572319488
(0, 5): -0.03837059409454777
(0, 7): -0.05054664648569062
(7,): -0.13708002916924827
(1,): -0.16588917661197009
(0,): -0.1961272149681774
)
Network Plot¶
shapiq.network_plot(interaction_values=iv, feature_names=list(X.columns))
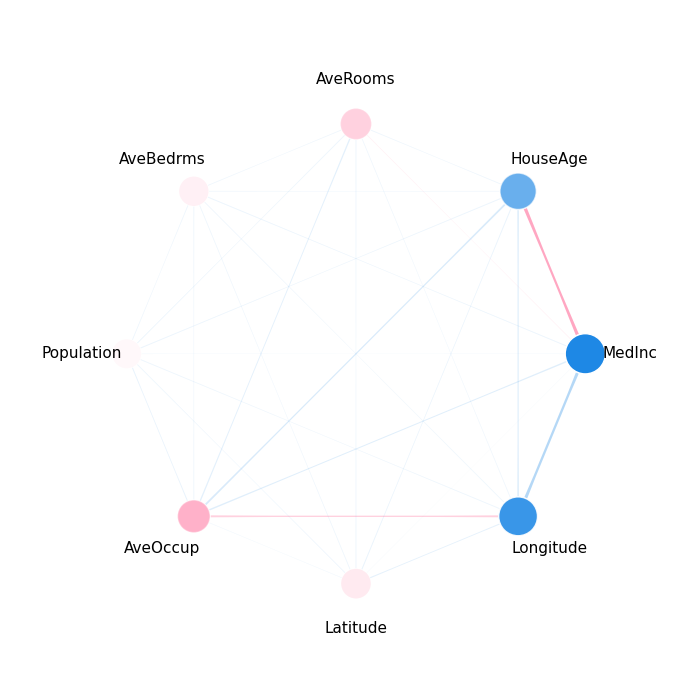
(<Figure size 700x700 with 1 Axes>, <Axes: >)
Total running time of the script: (1 minutes 0.812 seconds)